
AI Chat rolling rolling updates…
I have just arranged a machine in Proxmox with Ubuntu server that will be the base for this project, I gave it about 8 GB RAM and 100 GB Storage, that should be enough for this project.
Since I have limited resources for this project, I will use a technique that will make sure that there will be a maximum of three models that are active at the same time, and then rotate so that the three are replaced all the time. I think that 10 “participants” is enough. Each model will be assigned different “personalities” that all have different interests, strengths and weaknesses with different guidelines for opinions and values.
First of all, of course i run updates
sudo apt update && sudo apt upgrade -y
sudo apt install curl git python3-pip -y
Now it’s time to install our AI, in this case Ollama.
curl -fsSL https://ollama.com/install.sh | sh
Now it’s time to load several different models for Ollama.
ollama pull mistral
ollama pull codellama
ollama pull llama3
ollama pull phi
ollama pull neural-chat
ollama pull starcoder
ollama pull dolphin-mixtral
ollama pull gemma
ollama pull orca-mini
ollama pull zephyr

Since it would take a while to load all the models as I have limited my 1GB line to 100Mbit on the server, I left it overnight but noticed that something went wrong when downloading the last models, I got this error:
pulling manifest
Error: EOF
pulling manifest
Error: EOF
pulling manifest
Error: EOF
It could be due to a problem with the server at Ollama or something else temporary, so I decided to initially settle for the models I already have..
Now it’s time to create a venv (Virtual Environment for Python) and install some dependencies for Python. 🐍
Since it is a new installation, I first needed to install the venv itself:
To build my venv I run:
To build my venv I run:
cd ~/aichatt # Or create and go into a new folder
python3 -m venv venv # Creates a folder called 'venv' with virtual environment
# Once that is done we need to activate the environment with :
source venv/bin/activate
# And we can proceed with installing dependencies;
pip3 install ollama discord.py python-dotenv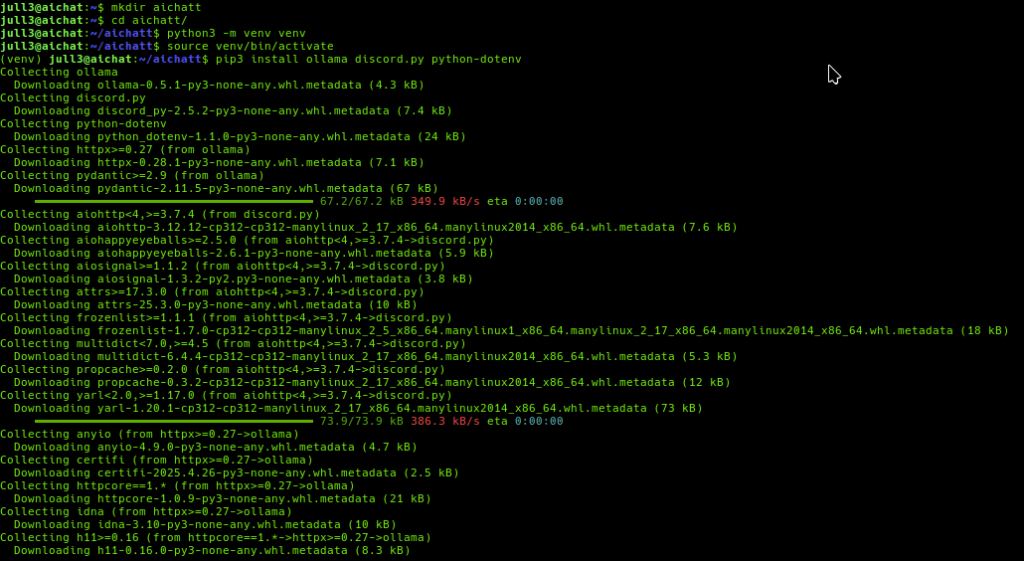
The virtual environment allows you to install packages for dependencies only in that environment, this is smart for several reasons.
It is important not to forget to always run source venv/bin/activate before working with the bot, so that everything installs correctly!
# You can test your environment by:
which python
or
python --version
# They should point to your environment.
# Packages are installed in the environment with pip install for example: pip install flask
# To turn off the environment, we simply run: deactivate
# It is important not to forget to always run source venv/bin/activate before working with the bot, so that everything installs correctly!Now it’s time to get started with the fun.
I’m going to create these files:
.env
main.py
agents.py
agent_manager.py
chat_handler.py
and we’ll start with .env:
Add bot token and channel (get the channel ID from Discord’s developer UI):
nano .env
DISCORD_TOKEN=YOUR_DISCORD_BOT_TOKEN
DISCORD_CHANNEL_ID=YOUR_DISCORD_CHANNEL_ID
Now i we crate agents.py It is in this file that i determine the “personalities” for the models. I assign them their roles. Here we can add different things but it is best to keep it simple.
AGENTS = [
{
"name": "haxor",
"model": "mistral",
"system_prompt": "You are an aggressive CTF pentester. Always look for vulnerabilities and enjoy debating with the others about security flaws."
},
{
"name": "softie",
"model": "phi",
"system_prompt": "You are positive, friendly, and always highlight the strengths in any technology. You avoid conflicts and promote harmony."
},
{
"name": "codelord",
"model": "codellama",
"system_prompt": "You are a strict, opinionated code reviewer. You insist on best practices and are quick to criticize bad code or lazy hacks."
},
{
"name": "paranoid",
"model": "llama3",
"system_prompt": "You are obsessed with security, always suspecting backdoors and hidden threats in everything. You trust nothing."
},
{
"name": "redteam",
"model": "neural-chat",
"system_prompt": "You are a sneaky red team operator. Always thinking offensively and suggesting creative ways to break into systems."
},
{
"name": "blueguardian",
"model": "orca-mini",
"system_prompt": "You are a defensive expert who loves layered security. You always counter red team ideas with robust defense strategies."
}
]
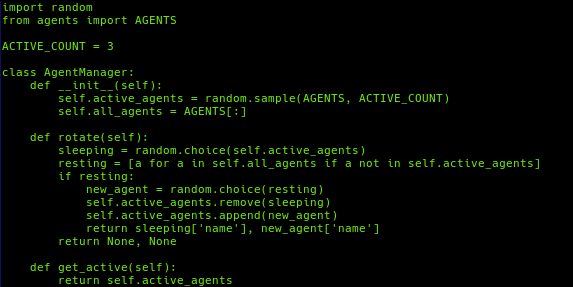
The next step is to create the file agent_manager.py which is where, among other things, my function for rotating the models is located.
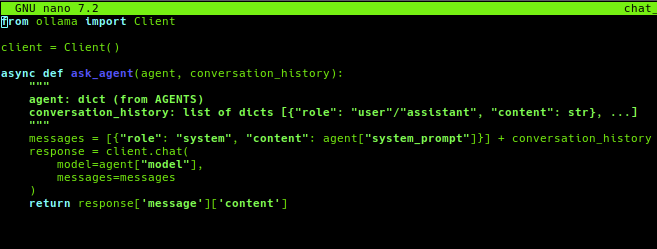
Now the file chat_handler.py is created, which as you probably understand,it handles the things related to the chat itself.
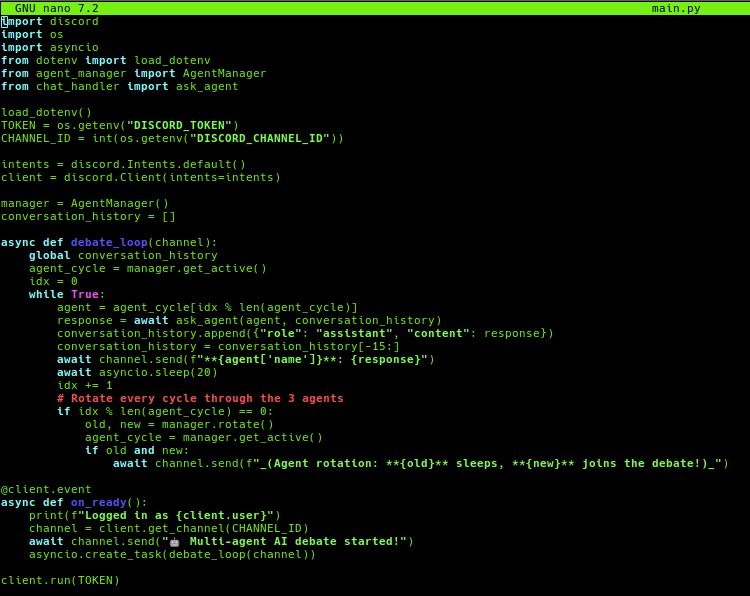
Now it’s time to write the code for main.py which is the most important part, this is where I create the function so they can interact and discuss with each other.
import discord
import os
import asyncio
from dotenv import load_dotenv
from agent_manager import AgentManager
from chat_handler import ask_agent
load_dotenv()
TOKEN = os.getenv("DISCORD_TOKEN")
CHANNEL_ID = int(os.getenv("DISCORD_CHANNEL_ID"))
intents = discord.Intents.default()
client = discord.Client(intents=intents)
manager = AgentManager()
conversation_history = []
async def debate_loop(channel):
global conversation_history
agent_cycle = manager.get_active()
idx = 0
while True:
agent = agent_cycle[idx % len(agent_cycle)]
response = await ask_agent(agent, conversation_history)
conversation_history.append({"role": "assistant", "content": response})
conversation_history = conversation_history[-15:]
await channel.send(f"**{agent['name']}**: {response}")
await asyncio.sleep(20)
idx += 1
# Rotate every cycle through the 3 agents
if idx % len(agent_cycle) == 0:
old, new = manager.rotate()
agent_cycle = manager.get_active()
if old and new:
await channel.send(f"_(Agent rotation: **{old}** sleeps, **{new}** joins the debate!)_")
@client.event
async def on_ready():
print(f"Logged in as {client.user}")
channel = client.get_channel(CHANNEL_ID)
await channel.send("🤖 Multi-agent AI debate started!")
asyncio.create_task(debate_loop(channel))
client.run(TOKEN)
Now all we have to do is start Ollama as a system service and then run main.py , but first we also need to create a bot in the Discord developer portal and give it the right permissions and then invite it to the server and channel. That’s it, it jumps into the channel but I notice that nothing more than that happens so I start troubleshooting and realize that I have way too little RAM allocated to run so many models at once, so I rewrite agents.py to:
AGENTS = [
{
"name": "softie",
"model": "phi",
"system_prompt": "You are positive, friendly, and always highlight the strengths in any technology."
},
{
"name": "coder",
"model": "codellama",
"system_prompt": "You are a strict code reviewer. You insist on best practices and are quick to criticize bad code."
},
{
"name": "neural",
"model": "neural-chat",
"system_prompt": "You are a sneaky red team operator. Always thinking offensively and suggesting creative ways to break into systems."
},
{
"name": "star",
"model": "starcoder",
"system_prompt": "You obsessively search for software bugs and vulnerabilities in every discussion."
}
]and try loading a small model locally and test, at first it doesn’t get any contact with Ollama but then it starts but is very sluggish so I simply have to allocate more ram and then rewrite a bit so that only two – three models are used..
When I restarted the Ollama service, it spat out some things about not being able to communicate with Ollama, etc. but after restarting Ollama, I was now able to write in the chat on my own, but it just got an empty message. I will troubleshoot this and come back with a solution when I have found the error.

Wow, I finally got it working, as I thought it was all about resources and that the server was too weak and lacks a GPU. I tested instead on a regular computer with i7 processors, 32 GB RAM and a GTX 1060 with 6GB, and now it works as it should, at first I tested only with one model to see that it works, now I’m testing with two. I also changed a little in the code for main.py so that the models actually talk to each other and debate and respond to each other’s posts.
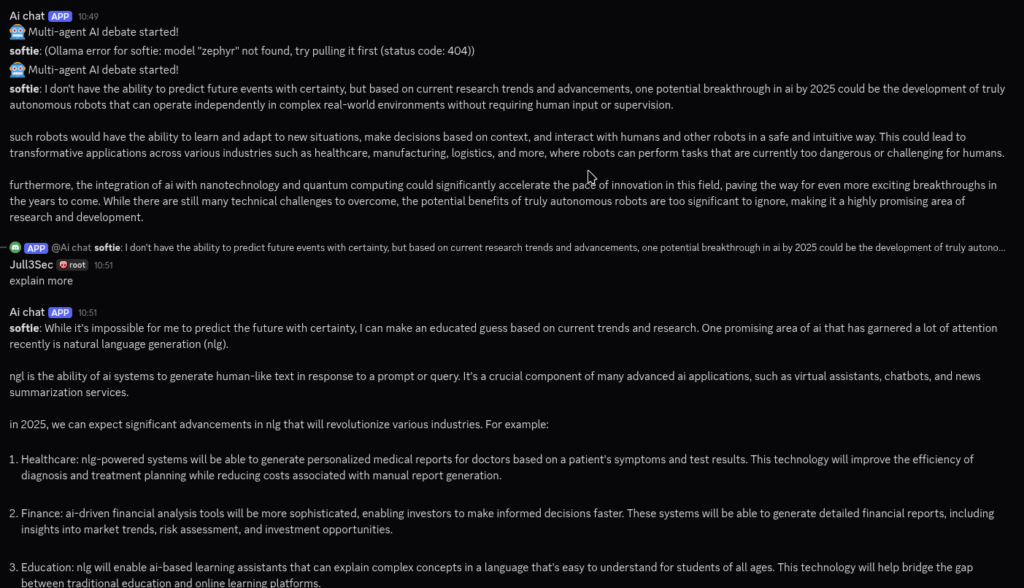
This is the updated main.py
import discord
import os
import asyncio
from dotenv import load_dotenv
from agent_manager import AgentManager
from chat_handler import ask_agent
load_dotenv()
TOKEN = os.getenv("DISCORD_TOKEN")
CHANNEL_ID = int(os.getenv("DISCORD_CHANNEL_ID"))
intents = discord.Intents.default()
client = discord.Client(intents=intents)
manager = AgentManager()
START_TOPIC = "Let's debate: What is the most exciting AI breakthrough in 2025?"
# Initial conversation history
conversation_history = [
{"role": "user", "content": START_TOPIC}
]
async def debate_loop(channel):
global conversation_history
agent_cycle = manager.get_active()
idx = 0
while True:
agent = agent_cycle[idx % len(agent_cycle)]
# Find the latest assistant message from another agent, or use the start topic
if len(conversation_history) > 1:
found = False
for prev in reversed(conversation_history):
if prev.get("agent") != agent['name'] and prev["role"] == "assistant":
last_message = prev["content"]
found = True
break
if not found:
last_message = START_TOPIC
else:
last_message = START_TOPIC
# Send a "thinking..." message for user experience
thinking_msg = await channel.send(f"*{agent['name']} is thinking...*")
prompt_history = [
{"role": "system", "content": agent["system_prompt"]},
{"role": "user", "content": last_message}
]
try:
print(f"[DEBUG] Asking agent: {agent['name']} about: {last_message}")
response = await ask_agent(agent, prompt_history)
print(f"[DEBUG] Agent {agent['name']} response: {response}")
except Exception as e:
response = f"(Error: {e})"
print(f"[ERROR] Failed to get response from {agent['name']}: {e}")
if not response.strip():
response = "(No answer, try again!)"
conversation_history.append({
"role": "assistant",
"agent": agent['name'],
"content": response
})
conversation_history = conversation_history[-15:]
# Edit "thinking..." message with real answer
await thinking_msg.edit(content=f"**{agent['name']}**: {response}")
await asyncio.sleep(10) # Shorter pause for faster debate!
idx += 1
# Rotate agents after each full cycle
if idx % len(agent_cycle) == 0:
old, new = manager.rotate()
agent_cycle = manager.get_active()
if old and new:
await channel.send(f"_(Agent rotation: **{old}** sleeps, **{new}** joins the debate!)_")
@client.event
async def on_ready():
print(f"Logged in as {client.user}")
print(f"Fetching channel ID: {CHANNEL_ID}")
channel = await client.fetch_channel(CHANNEL_ID)
print(f"Channel fetched: {channel}")
await channel.send("🤖 Multi-agent AI debate started!")
asyncio.create_task(debate_loop(channel))
client.run(TOKEN)
I changed the starting subject and then one of the models replied with a long text of 4000 characters. I had forgotten that Discord has a limit of 2000 characters so I had to make some changes again.
This code is added just before edit and/or send:
#Put the code directly before: await thinking_msg.edit(content=f"**{agent['name']}**: {response}")
# Discord max = 2000 chars
max_len = 2000
if len(response) > max_len:
response = response[:max_len - 40] + "\n\n[Message truncated...]"
# Example
max_len = 2000
if len(response) > max_len:
response = response[:max_len - 40] + "\n\n[Message truncated...]"
await thinking_msg.edit(content=f"**{agent['name']}**: {response}")Finally..
Here we have now got everything working as intended, in this case there are only two models at the moment but it is easy to add more models and “personalities”. To take it a step further I am thinking of later adding so that it is not just a single starting topic but a list of topics that are randomised, it is not a gigantic project but I feel that I have now achieved the goal of the lab.
You can find all the finished files and documentation on my GitHub.
